はい こんにちは! KiYOです。
今回は、AWSのデータベースについてです。
AWSのデータベースは多種多様のデータベースが用意されています。
最適なデータベースの選択を実施するために様々なデータベースのタイプとその活用方法を
解説していきます。
ちょっとボリュームが多いので何回かに分けてまとめて行きます。
では。
データベースとは
まず、データベースの定義というと
データベースは関連したデータを形式を揃えて収集・整理して、検索などの操作やデータ管理を実行するシステムのことを言います。
データベースはリレーショナルDBとNoSQLの2つに分類されます。
リレーショナルDB
データベースの基本はリレーショナル DBシステム(RDBS)
データ間の関係性が定義されたデータを取り扱う一般的なDBシステム
列と行がいくつかのテーブルで定義されていて、テーブル間のリレーションが設定さている
データ操作にはSQLが用いられる
業務系システム全般に使われており、会計データや顧客データといった構造化データの場合に用いられます。
NoSQL
ビッグデータ解析などにはNoSQLが利用されます
リレーショナルデータ構造をもたず、SQLを利用しないDBの総称
ただし、現在はSQLやSQLに似たモデルもあります。
構造化されていないKeyとValueのみのKVSデータ
(ID番号に1列に全データを格納)
動画・画像・ドキュメントなどの非構造化データや
XML・JSONなどの半構造化データに用いられます。
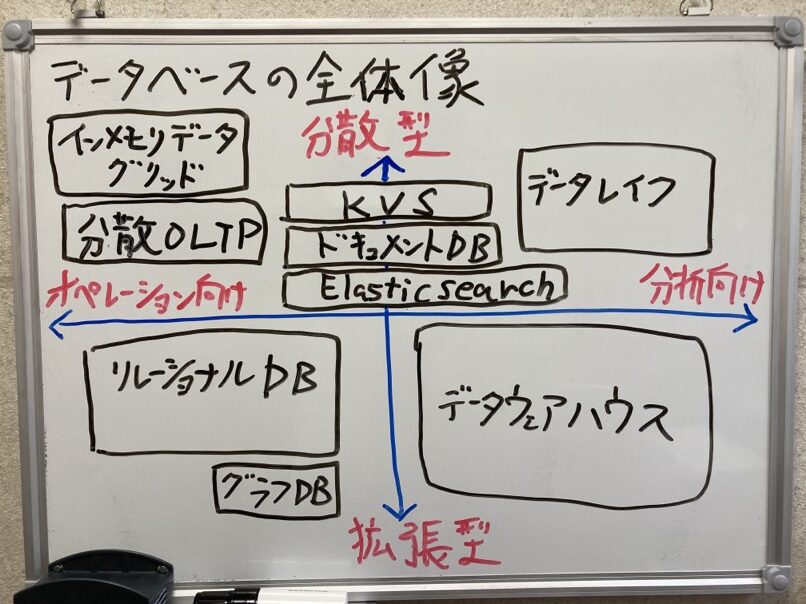
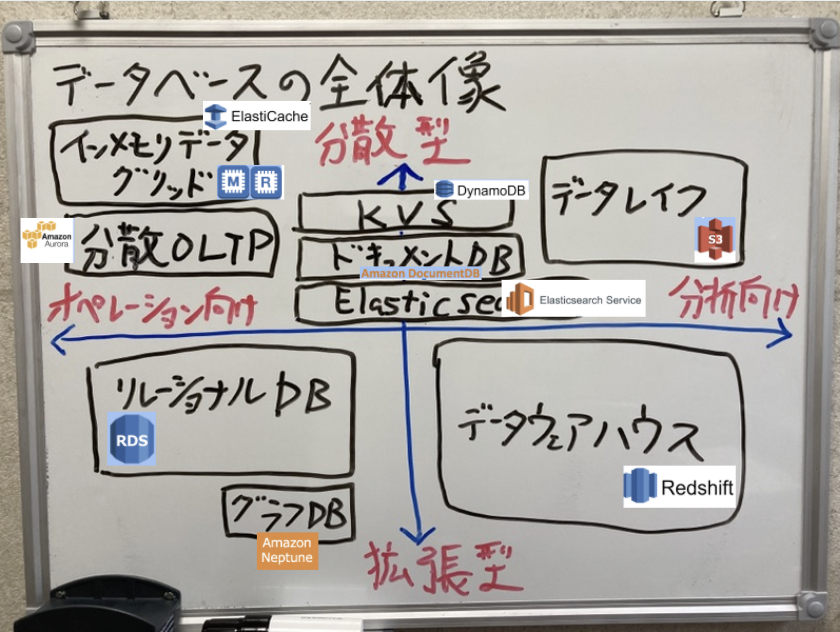
データベース全体像
リレーショナルDB(RDB)
業務システム向けのDBの基本はリレーショナルデータベース
【概要】
業務システムなどで最も頻繁に利用されるオペレーション用のデータベース
利用者はSQLなどのクエリ言語でデータ操作を実施する
【アーキテクチャ】
テーブル間のリレーションが定義されたデータモデル
行指向で1つの行をデータの塊として取り扱う
【利用シーン】
会計データなどの業務系構造化データで使用されるシーンが多いです。
AWSのサービスとしては、RDSとして以下の様なデータベースシステムが用意されています。
- Oracle
- SQLServer
- MySQL
- PostgreSQL
データウェアハウス(DWH)
構造化データを利用した経営分析向けのデータベース
【概要】
データの抽出・集約に特化したBIデータ分析用のデータベース
読み込むデータ構造をあらかじめ設計して、加工してから利用分のデータを蓄積
レスポンス重視でデータ抽出・集計が早いが、更新・トランザクションは遅い
【アーキテクチャ】
データをパーティショニングして、複数ディスクから読み込む
列指向でデータを格納
【利用シーン】
会計データなどの業務系の構造化データを分析用に加工し、BIで利用
KPI測定/競合分析/アクセス分析などに利用
【オンプレ】
- Oracle
- VERTICA
- TERADATA
- Greenplumなど
【AWSサービス】
- RedShift
分散型DB/データレイク
ビッグデータやIoTデータを蓄積して高速処理を可能にするDBとストレージの組み合わせ
【概要】
データ抽出に特化したDB
分散してデータを保存しており、ビッグデータの高速処理向け
【アーキテクチャ】
SQLライクなクエリで操作可能
INSERT/UPDATE/DELETEはない
トランザクションはない
データ書き込みは一括ロードまたは全件削除のみ
【利用シーン】
ビッグデータ
【オンプレ】
- Impala
- HIVE
- presto
- HDFS
【AWSサービス】
- RedShift
KVS:キーバリュー型
シンプルなデータ構造にすることで高速処理を可能にしたDB
【概要】
分散して、シンプルなオペレーションを高速に実施できるDB
【アーキテクチャ】
強い整合性を犠牲にして、結果的な整合性を採用
分散向けのデータモデル/クエリの採用
トランザクション/集計/JOINなど不可
【利用シーン】
大規模Webサイトのバックエンドデータ
ユーザセッション/ユーザ属性/事前計算データのキャッシュ
メッセージングシステムのデータ
大規模書き込みが必要なIoTセンサーデータなど
【オンプレ】
- redis
- riak
【AWSサービス】
- ElastiCache
- DynamoDB
ワイドカラム型
キーに対してカラムを大規模に登録できるのがワイドカラム型
【概要】
分散して、シンプルなオペレーションを高速に実施できるDB
データ取得する際にデータ結合しなくても済むように、可能な限り多くのデータを同じ行に保持
【アーキテクチャ】
結果整合性を採用
キースペース、カラムファミリ、ロウ、(スーパーカラム)、カラムの入子構造
SQLライクなデータ操作が可能
データ操作は挿入、削除、参照のみで、データの更新は挿入による上書き
【利用シーン】
Facebook/Twiiterなどソーシャルデータの位置情報データストレージ
リアルタイム分析、データマイニング処理
【オンプレ】
- cassandra
- apache HBASE
【AWSサービス】
- DynamoDB
ドキュメントDB
キーに対してドキュメント指向でXMLなどのデータを格納する
【概要】
ドキュメント指向データベースでは、様々なデータ構造のドキュメントを混在して保存することができる
【アーキテクチャ】
JSON・XMLをデータモデルに利用
小規模データの同期集計処理が可能だが、バッチは不向き
SQLライクなデータ操作が可能で、SVSよりもクエリが豊富なため操作しやすい
Shardingによるデータベース分散化
【利用シーン】
半構造化データ(XML・JSON)
大規模WEBのログ保管など
オンラインゲームデータ
カタログ管理
【オンプレ】
- mongoDB
- MarkLogic
- CouchDB
- CouchBase
【AWSサービス】
- Amazon DocumentDB
- MongoDB
インメモリデータグリッド
KVSの仕組みをメモリを利用してより高性能にしたDB
【概要】
大量のデータを多数のサーバのメモリ上で分散して管理する技術
ミリ秒単位の高速の応答処理が可能
【アーキテクチャ】
データをメモリ上に置くことで、高速なデータアクセスを実現
データを多数のサーバで分散して管理
【利用シーン】
金融の取引データをミリ秒以下の応答時間を実現
【オンプレ】
- Apache GEODE
- Oracle Coherence
- hazelcast
- apache lgnite Onfinispon
【AWSサービス】
- Redis ElastiCache
- Memcached ElastiCache
全検索型エンジンx分散DB
データの全検索エンジンであるElasticsearchは分散データベースとして連携してデータ全検索処理が可能
【概要】
全検索型のデータ検索エンジンで、分散データベースと連携して検索データベースを構築
検索条件との関係性/関連性が高いデータを抽出して返す
【アーキテクチャ】
Elasticsearchは全文検索用のライブラリApache Luceneを利用したデータストア
分析の柔軟性や速度が高く、分析・蓄積・可視化環境を容易に構築可能
【利用シーン】
半構造化データ(XML・JSON)
高可用な全検索エンジン
サイト内データの検索
デバイス登録状況・配信状況のリアルタイム可視化などリアルタイムの検索要件/検索行動の可視化
【オンプレ】
- elasticsearch
- kibana
【AWSサービス】
- Elasticsearch Service
グラフDB
グラフ構造でデータ間のつながりを検索・可視化するDB
【概要】
グラフ演算に特化したDBで、データ間の繋がり方を検索・可視化に利用
【アーキテクチャ】
グラフデータ構造を取るため、RDB以上にスケールアウトできない
レコード数が増えると、検索にかかる時間と難易度が増大
ACID特性が担保されており、オブエクト間の関連付けを簡単に表現できる
【利用シーン】
最短経路探索
金融取引の詐欺検出
ソーシャルネットワークによるリレーション計算
【オンプレ】
- neo4j
【AWSサービス】
- Amazon Neptune
分散OLTP(RDB)
オンライントランザクション処理(Online Trasaction Processing)を分散化する次世代DB
【概要】
グローバルに分散され、強整合性を備えたデータベース
【アーキテクチャ】
リレーショナルデータベースお構造と非リレーショナルデータベースの分散スケーラビリティを兼ね備える高い可用性、高性能のトランザクションと強整合性が実現
【利用シーン】
大規模な業務データ処理
【AWSサービス】
- AmazonAurora
まとめ
これまで、全10タイプのデータベースの概要・アーキテクチャを説明してきました。
- リレーショナルDB(RDB)
- データウェアハウス(DWH)
- 分散DB/データレイク
- KVS:キーバリュー型
- ワイドカラム型
- ドキュメントDB
- インメモリデータグリッド
- 全検索型エンジンx分散DB
- グラフDB
- 分散OLTP(RDB)
利用シーンやAWSサービスとの関係性を理解し、最適なデータベースの選択が出来ることがポイントです。
この後は、よく使われるAWSサービスのデータベースについて解説して行きます。
次回は、「DynamoDB」です。

前回は「Route53」です。


コメント