データ分析を行う上で、生データの保護、代表値の把握、そして可視化は不可欠なステップです。本ドキュメントでは、これらのステップを具体的な関数や手法を交えながら解説し、データから客観的な判断を下すためのスキルを習得するための道筋を示します。アンケート分析を例に、これらのテクニックを習得することで、効率的にデータ分析を進めることができるようになります。
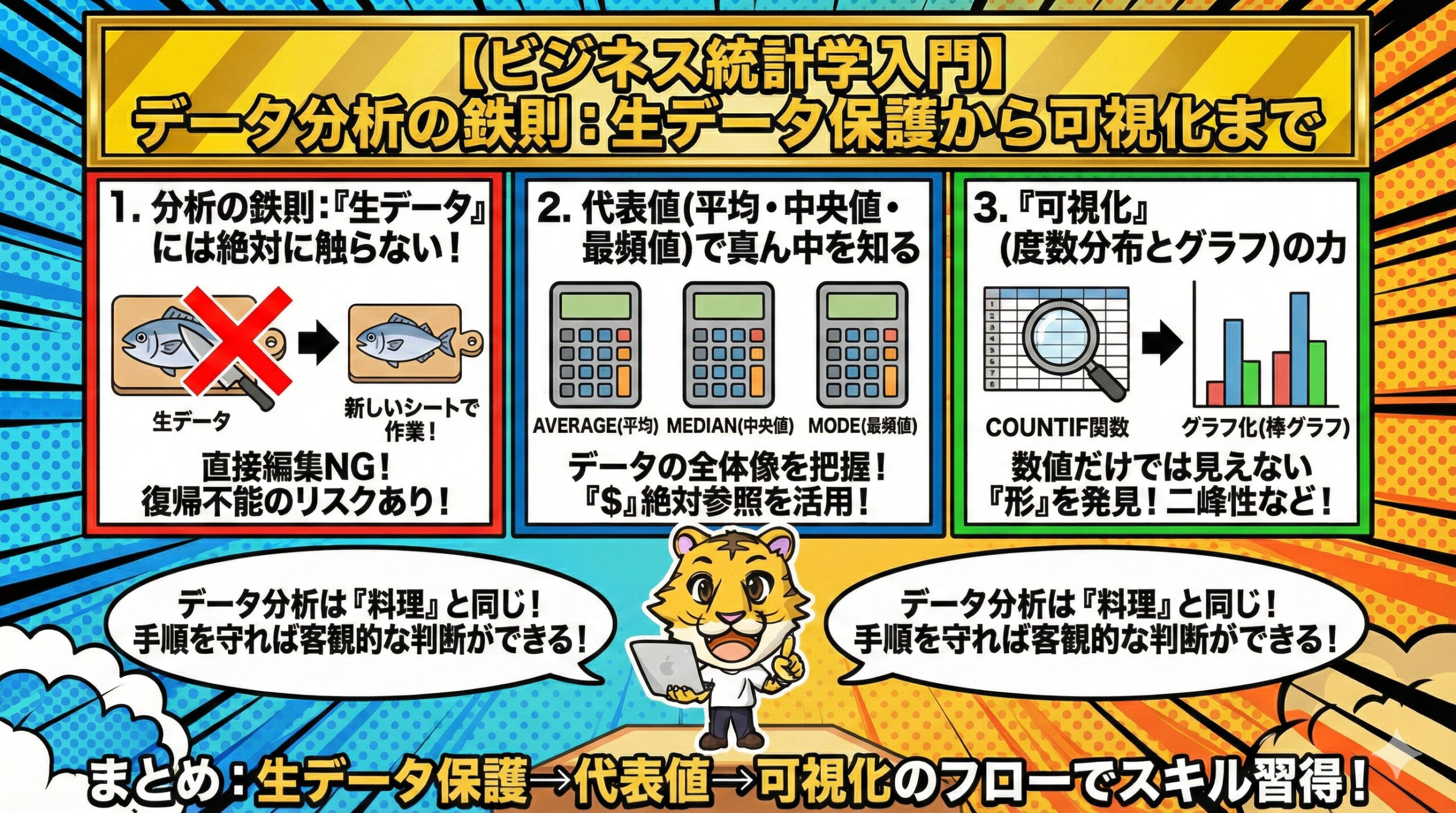
1. 分析の鉄則:生データには絶対に触らない
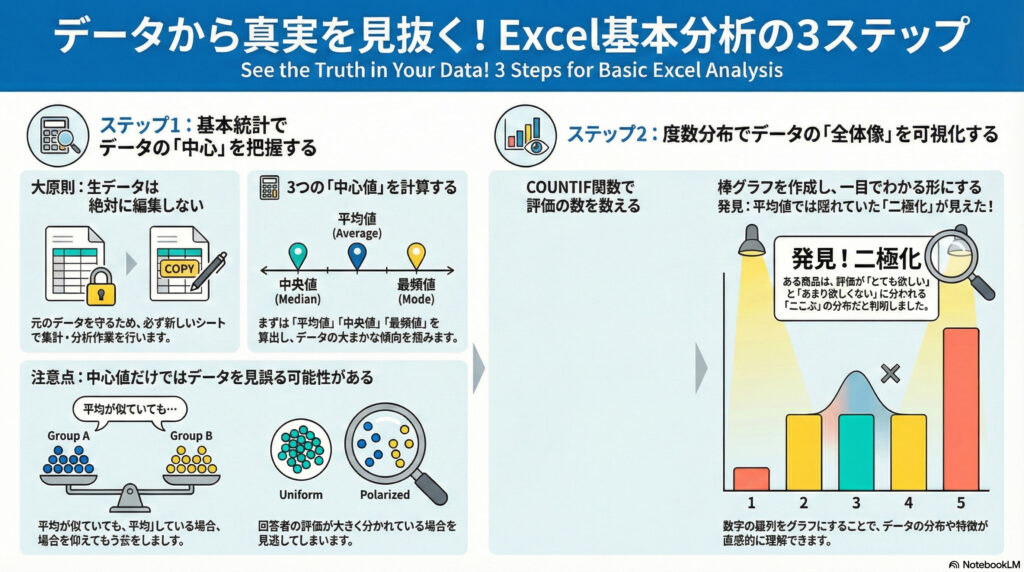
データ分析を始める前に、最も重要な大原則があります。それは、**「生データ(Raw data)を直接編集しない」**ということです。
理由: 誤ってデータを消去したり書き換えたりすると、元の状態に復帰できなくなり、重要な情報が失われるリスクがあるためです。
対策: 必ず新しいシートを作成し、そこにデータを参照・集計する形で作業を進めましょう。
2. 代表値(平均・中央値・最頻値)で真ん中を知る
データの全体像を把握するための第一歩は、平均値などの代表値を求めることです。
- 平均値 (AVERAGE関数): 全体の平均的な数値を確認します。
- 中央値 (MEDIAN関数): データを大きさ順に並べた時、ちょうど真ん中に位置する値です。
- 最頻値 (MODE関数): データの中で最も頻繁に現れる値です。
これらの数値を算出する際、「$(ドルマーク)」を使った絶対参照を活用すると、数式をコピーしても範囲がずれず、効率的に作業を進めることができます。平均値だけでは見えないデータの偏りも、中央値や最頻値を合わせることでより明確になります。
3. 度数分布とグラフによる「可視化」の力
数値の集計だけでなく、**度数分布(どの数値が何件あるか)**を確認し、グラフ化することが非常に重要です。
- COUNTIF関数: 「1と答えた人は何人か?」といった条件に合う件数を自動でカウントできます。
- グラフ化: 集計した度数分布表をもとに棒グラフを作成します。
なぜ可視化が必要なのか?
例えば、ある商品の平均値が「3」だったとしても、全員が「3」と答えたのか、それとも「1(いらない)」と「5(欲しい)」で意見が真っ二つに分かれた結果の「3」なのかは、平均値だけでは判断できません。「二峰性(ふたつの山)」があるような特殊な分布は、度数分布やグラフを見なければ気づけない重要な発見です。
4. まとめ
これらの手順を習得すれば、50名程度のアンケート分析ならわずか20分ほどで完了させることができます。
- 新しいシートで分析を始める。
- AVERAGE, MEDIAN, MODEで代表値を出す。
- COUNTIFで度数分布を作り、グラフで形を見る。
このシンプルなフローを繰り返すことで、データから客観的な判断を下すスキルが身につきます。
——————————————————————————–
例えるなら: データ分析は「料理」によく似ています。生データは「貴重な食材」であり、それを汚さないように別のまな板(新しいシート)で調理します。平均値などの代表値は「味見」のようなものですが、盛り付け(グラフ化)をしてみることで、初めてその料理の本当の姿や隠れた特徴が誰の目にも明らかになるのです。




コメント